Data mining merupakan 2 kata yang berasal dari kata "data" dan "mining". Data merupakan sekumpulan informasi, fakta, serta pengetahuan bersifat real atau fakta. Sedangkan mining berarti memperoleh atau mengelola data yang telah dicari dan diproses menjadi pengetahuan. Data mining memiliki banyak sekali metode-metodenya adapun diantaranya klasifikasi, klastering, asosiasi, dan beberapa lainnya.
Contoh kecil penggunaan data mining dalam kehidupan perkuliahan adalah mendata kelas bagi mahasiswa. Dimana akan diperlukan nim dan nama dan akan digunakan untuk pengurutan absen dikelas tersebut.
Pertemuan 1 - Pengantar
ASSALAMMU'ALAIKUM WR. WB
Apa kabar teman-teman semua? Semoga teman-teman diberi kesehatan selalu ya.. Pada pertemuan ke 1 ini kita akan membahas pengantar data mining.
Pada abad ke-21 ini data sudah terbuat dan/atau terkumpul dari berbagai sumber. Data terbuat terus dari detik ke detik dalam 24 jam dalam sehari. Pada tahun 2020 ini, diprediksi dihasilkan sekitar 35 zettabytes (10 bytes atau 1.000.000.000.000.000.000.000 bytes) dari seluruh dunia (IBM Cognitive Class-2, 2020). Fenomena ini menyebabkan "Ledakan Data", akan tetapi banyak yang tidak menyadari dari data-data tersebut kita dapat menggali informasi / memanfaatkan potensi dari suatu data, kita kaya akan data tetapi miskin informasi.
Data Mining merupakan Disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data yang besar. Dengan contoh kasus yang dibahas pada pertemuan kali ini akan memberikan gambaran kepada teman-teman bagaimana data mining dapat memberikan kita informasi yang berguna sehingga dapat menjadi pendukung pengambilan keputusan.
Pada tahapan keberapakah "Nyatakan tujuan dan persyaratan proyek dengan jelas dalam kaitannya dengan bisnis atau unit penelitian secara keseluruhan" dalam tahapan data mining?
a. Data Understanding
b. Deployment
c. Business Understanding
d. Preparation
e. Data Preparation
f. Modelling
Jawab: C
Soal 2
Berikut ini merupakan contoh dari Interval (jarak), yaitu...
a. Berat badan
b. Umur
c. Jumlah Uang
d. Tinggi badan
e. Umur 20-30 tahun
Jawab: E
Soal 3
Berikut ini merupakan contoh dari ratio (mutlak), kecuali...
a. Berat badan
b. Jumlah uang
c. Tinggi badan
d. Umur
e. Tingkat kepuasan pelanggan (puas, sedang, tidak puas)
Jawab: E
Soal 4
Salah satu standard proses di dunia data mining dalam dunia industri adalah...
a. Key Performance Indicator (KPI)
b. CRISP–DM
c. Tableu
d. Oracle
Jawab: B
Soal 5
Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan, merupakan contoh penggunaan metode data mining berupa...
a. Asosiasi
b. Klasifikasi
c. Prediksi
d. Pengklusteran
e. Estimasi
Jawab: A
Soal 6
Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan, merupakan contoh dari metode data mining berupa..
a. Pengklusteran
b. Estimasi
c. Asosiasi
d. Klasifikasi
e. Prediksi
Jawab: B
Soal 7
Apa yang dimaksud dengan tipe data diskrit?
a. Data yang diperoleh dengan cara kategorisasi atau klasifikasi
b. Data yang diperoleh dari nilai yang berada di luar jangkauan data lainnya
c. Data yang diperoleh dari nilai korelasi antar variabel
d. Data yang diperoleh dengan cara pengukuran, dimana jarak dua titik pada skala sudah diketahui
e. Data yang diperoleh dari nilai perankingan
Jawab: A
Soal 8
Apa yang dimaksud dengan tipe data kontinyu?
a. Data yang diperoleh dari nilai perankingan
b. Data yang diperoleh dari nilai yang berada di luar jangkauan data lainnya
c. Data yang diperoleh dari nilai korelasi antar variabel
d. Data yang diperoleh dengan cara kategorisasi atau klasifikasi
e. Data yang diperoleh dengan cara pengukuran, dimana jarak dua titik pada skala sudah diketahui
Jawab: E
Pertemuan 3 - Preprocessing Data
Assalammu'alaikum wr. wb.
Hai teman-teman, kita bertemu kembali di pertemuan ke 3 yaa.. kali ini kita akan membahas Preprocessing Data. Preprocessing data sangat penting karena kesalahan, redundan, missing value, dan data yang tidak konsisten menyebabkan berkurangnya akurasi hasil analisis. Jadi, sebelum mengolah data, kita harus memastikan bahwa data yang akan kita gunakan merupakan data "bersih".
Tugas data mining sebenarnya adalah analisis otomatis atau semi-otomatis jumlah besar data untuk mengekstrak pola yang menarik yang sebelumnya tidak diketahui seperti kelompok catatan data (analisis cluster), catatan yang tidak biasa (deteksi anomali) dan dependensi (aturan asosiasi pertambangan).
Hal ini biasanya melibatkan menggunakan teknik database seperti indeks spasial. Pola ini kemudian dapat dilihat sebagai semacam ringkasan dari input data, dan dapat digunakan dalam analisis lebih lanjut atau, misalnya, dalam pembelajaran mesin dan analisis prediktif. Misalnya, langkah data mining mungkin mengidentifikasi beberapa kelompok dalam data.
Dalam pertemuan ke 4 ini kita akan membahas beberapa metode yang diterapkan dalam data mining.
Pertemuan 5 - Naive Bayes
Assalammu'alaikum wr. wb.
Pertemuan ke 5 ini kita akan membahas mengenai Bayesian Classification. Bayesian Classification adalah pengklasifikasian statistic yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Algoritma yang digunakan salah satunya adalah Naive Bayes. Bayesian Classification terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar.
Salah satu contoh penggunaan algoritma Naive Bayes adalah memprediksi apakah seseorang dengan kriteria tertentu akan membeli komputer atau tidak berdasarkan nilai probabilitas keanggotaan classnya.
Pada pertemuan kali ini akan ada 2 sesi, yaitu :
1. SESI MATERI
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma Naive Bayes.
2. SESI PRAKTIKUM
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma Naive Bayes dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Social Network Ads. csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
Berikut ini pernyataan yang benar tentang Bayesian Classification, kecuali...
a. Bayesian Classification adalah pengklasifikasian statistic yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class
b. Bayesian classification didasarkan pada teorema Bayes yang memiliki kemampuan klasifikasi serupa decision tree dan neural network
c. Naive Bayes dapat mengolah data dengan target/class/label berupa nilai numerical
d. Bayesian Classification terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar
e. Bayesian Classification termasuk dalam metode learning unsupervised learning
Jawab: E
Soal 2
Apakah Naive Bayes efektif untuk mengatasi data dengan banyak fitur numerik?
a. Naive Bayes bisa untuk data numerik dan kategoris
b. Ya, Naive Bayes sangat efektif untuk data numerik.
c. Tergantung pada jumlah kelas dalam data.
d. Tidak, Naive Bayes lebih cocok untuk data dengan fitur kategoris.
e. Tidak, Naive Bayes kurang efektif untuk data dengan banyak fitur numerik.
Jawab: E
Soal 3
Pada nomor berapa yang menunjukkan target/class/label?
a. 3
b. 4
c. 2
d. 1
Jawab: D
Soal 4
[pilih 2 jawaban benar] Manakah yang merupakan tipe data kategorikal?
a. Jenis kelamin
b. Tingkat kepuasan pelanggan (puas, sedang, tidak puas)
c. Umur
d. Suhu 0°c-100°c,
e. Berat badan
Jawab: A dan B
Soal 5
"Algoritma Naive Bayes termasuk Metode Learning Klasifikasi".
Apakah pernyataan ini benar atau salah?
Pilih satu:
a. Benar
b. Salah
Jawab: A
Pertemuan 6 - K - Nearest Neighbor (KNN)
ASSALAMMU'ALAIKUM WR. WB.
Salah satu algoritma yang dapat digunakan untuk metode learning Klasifikasi adalah K - Nearest Neighbor (KNN). KNN merupakan pendekatan untuk mencari kasus lama, yaitu berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada.
Salah satu contoh KNN adalah untuk mencari solusi terhadap pasien baru dengan menggunakan solusi dari pasien terdahulu dengan menghitung kedekatan kasus pasien baru dengan semua kasus pasien lama. Kasus pasien lama dengan kedekatan terbesarlah yang akan diambil solusinya untuk digunakan pada kasus pasien baru.
Yuk kita sama-sama pelajari bagaimana algoritma KNN bekerja. Pada pertemuan kali ini akan dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma KNN.
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma KNN dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Social Network Ads. csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
KNN dapat digunakan untuk memproses data kategorikal.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 2
KNN merupakan algoritma Supervised Learning yang memanfaatkan data latih untuk melakukan prediksi pada data uji.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 3
K-Nearest Neighbor (KNN) merupakan algoritma Machine Learning yang dapat digunakan untuk klasifikasi dan regresi.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 4
K-NN mengklasifikasikan suatu data dengan mencari k-tetangga terdekat dan menentukan label kelas yang paling sering muncul di antara tetangga tersebut.
Pernyataan tersebut berilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 5
KNN termasuk dalam kategori algoritma parametrik karena membutuhkan nilai K sebagai parameter.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: B
Pertemuan 7 - Decision Tree (C4.5)
ASSALAMMU'ALAIKUM WR. WB
Alhamdulillah kita kita masih diberi kesempatan untuk bertemu pada pertemuan ke 7. Masih semangat ya teman-teman..
Pada pertemuan kali ini kita akan membahas tentang algoritma C4.5. Algoritma C4.5 merupakan algoritma yang digunakan untuk membentuk pohon keputusan (Decision Tree). Pohon keputusan merupakan metode klasifikasi dan prediksi yang terkenal. Pohon keputusan berguna untuk mengekspolari data, menemukan hubungan tersembunyi antara sejumlah calon variable input dengan sebuah variable target.
Salah satu contoh penggunaan algoritma C4.5 adalah membuat pohon keputusan untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca, temperatur, kelembaban dan keadaan angin.
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma Decision Tree C.45
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma Decision Tree C.45 dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Dataset Iris.csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
C4.5 merupakan algoritma yang digunakan untuk membangun decision tree.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 2
C4.5 dapat digunakan untuk estimasi.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: B
Soal 3
C4.5 hanya cocok untuk memproses data kategorikal.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: B
Soal 4
C4.5 menghasilkan decision tree yang mudah dipahami dan diinterpretasikan oleh manusia.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Soal 5
Entropy dapat dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas.
Pernyataan tersebut bernilai True atau False?
a. Benar
b. Salah
Jawab: A
Ujian CPMK 1
Soal 1
Pengertian Data adalah...
a. penjelasan, rangkuman, rekap dan statistic dari data
b. Hasil yang diperoleh dari preprocessing
c. fakta yang terekam dan tidak membawa arti
d. pola, aturan atau model yang muncul dari data
Jawab: C
Soal 2
Pada tahapan keberapakah "Nyatakan tujuan dan persyaratan proyek dengan jelas dalam kaitannya dengan bisnis atau unit penelitian secara keseluruhan" dalam tahapan data mining?
a. Business Understanding
b. Data Preparation
c. Preparation
d. Modelling
e. Deployment
f. Data Understanding
Jawab: A
Soal 3
Salah satu standard proses di dunia data mining dalam dunia industri adalah...
a. CRISP–DM
b. Key Performance Indicator (KPI)
c. Tableu
d. Oracle
Jawab: A
Soal 4
Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan, merupakan contoh penggunaan metode data mining berupa...
a. Prediksi
b. Asosiasi
c. Estimasi
d. Pengklusteran
e. Klasifikasi
Jawab: B
Soal 5
Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan, merupakan contoh dari metode data mining berupa..
a. Estimasi
b. Asosiasi
c. Pengklusteran
d. Prediksi
e. Klasifikasi
Jawab: A
Soal 6
Berikut ini merupakan pernyataan mengapa diperlukannya 'data cleaning' dalam preprocessing data, kecuali...
a. Data baik menghasilkan output yang akurat
b. Berpengaruh pada nilai presisi dan kinerja data mining Memecah ketidakkonsistenan data
c. Data awal pada umumnya “kotor”
d. Menghilangkan outlier / noise
e. Menyatukan data dari berbagai database / server
Jawab: B
Soal 7
Rudi mendapatkan dataset yang diambil dari rumah sakit tempat Rudi melakukan penelitian. Dataset yang diperoleh Rudi merupakan jenis dataset?
a. Comparable
b. Private Dataset
c. Repeatable
d. Verifiable
e. Public Dataset
Jawab: B
Soal 8
Data set dapat diambil dari repository public yang disepakati oleh para peneliti data mining merupakan pengertian dari jenis dataset...
a. Repeatable
b. Public dataset
c. Private Dataset
d. Verifiable
e. Comparable
Jawab: B
Soal 9
Berikut ini merupakan tahapan yang benar dalam tahapan utama data mining adalah...
a. Metode - Input - Output - Evaluation
b. Metode - Evaluation - Input - Output
c. Input - Metode - Output - Evaluation
d. Evaluation - Metode - Input - Output
e. Input - Evaluation - Output - Metode
Jawab: C
Soal 10
Suatu supermarket mempunyai sejumlah transaksi seperti di dalam tabel berikut.
Maka terbentuklah association rule,
Jika membeli roti maka membeli mentega
Jika membeli mentega maka membeli roti
Jika membeli coklat maka membeli susu
Jika membeli roti dan susu maka membeli mentega
Jika membeli mentega dan susu maka membeli roti
Dataset tersebut dapat diselesaikan dengan algoritma?
a. Linear Regression
b. Neural Network
c. A priori algorithm
d. Support Vector Machine
e. K-Nearest Neighbor
Jawab: C
Soal 11
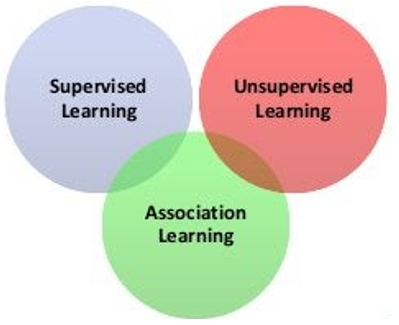
Suatu pendekatan dalam pembuatan AI dimana algoritma melakukan proses belajar berdasarkan nilai dari variable target yang terasosiasi dengan nilai dari variable predictor. Merupakan pengertian dari...
a. Supervised Learning
b. Association Learning
c. Prediction / forecasting
d. Unsupervised Learning
e. Classification
Jawab: A
Soal 12
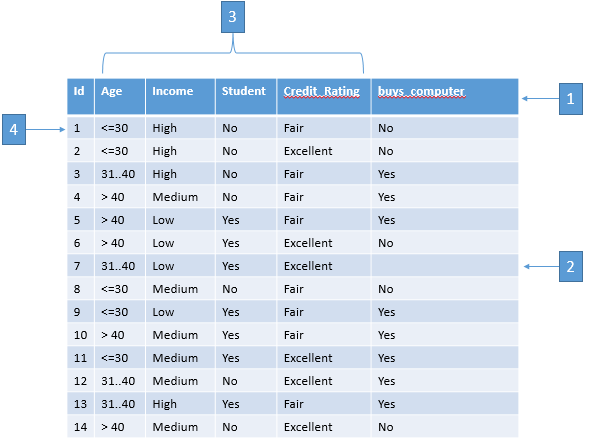
Pernyataan berikut yang benar dari dataset di atas adalah...
a. Variable (atribut) yang menjadi target/label/class sudah ditentukan (ada)
b. Variable (atribut) yang menjadi target/label/class tidak ditentukan (tidak ada
c. Termasuk metode learning masalah pembelajaran diawasi atau terbimbing
d. Algoritma estimation, prediction/forecasting, classification dapat diselesaikan dengan menggunakan metode learning ini.
Jawab: A
Soal 13
Data yang berada di luar jangkauan data yang diharapkan disebut dengan istilah...
a. Outlier
b. Noise
c. Missing values
d. Contradictory examples
e. Reduction
Jawab: A
Soal 14
Berikut ini yang bukan termasuk disiplin ilmu dari Data Mining, adalah...
a. Artificial Intelligence
b. Biologist
c. Pattern Recognition
d. Machine Learning
e. Statistic
Jawab: B
Soal 15
Berikut ini merupakan pernyataan yang salah adalah...
a. Informasi berisi penjelasan, rangkuman, rekap dan statistic dari data
b. Data merupakan fakta yang terekam dan tidak membawa arti
c. Data mining merupakan kegiatan menyimpan data suatu server
d. Data Mining merupakan disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data yang besar.
e. Pengetahuan berisi pola, aturan atau model yang muncul dari data.
Jawab: C
Soal 16
Jelaskan apa yang dimaksud dengan data mining? Bagaimana data mining berbeda dari pengolahan data konvensional?
Jawab:
Data mining adalah proses mengeksplorasi dan menganalisis data besar untuk menemukan pola, informasi, atau pengetahuan yang bermanfaat. Ini melibatkan penggunaan teknik statistik, kecerdasan buatan, dan algoritma lainnya untuk mengidentifikasi hubungan atau pola yang tidak terlihat secara langsung.
Perbedaan utama antara data mining dan pengolahan data konvensional adalah bahwa pengolahan data konvensional lebih fokus pada pengelolaan, penyimpanan, dan manipulasi data untuk tujuan tertentu, sementara data mining lebih fokus pada analisis yang mendalam untuk mengeksplorasi data dan menemukan informasi yang tersembunyi. Data mining menekankan pada penggunaan algoritma dan teknik khusus untuk mengekstrak pengetahuan dari data yang besar dan kompleks.
Sebutkan dan jelaskan setidaknya tiga algoritma klasifikasi populer dalam data mining. Bagaimana masing-masing algoritma bekerja?
Jawab:
1. Decision Tree (Pohon Keputusan):
- Cara kerja: Algoritma ini membagi data menjadi kelompok-kelompok yang lebih kecil berdasarkan serangkaian keputusan berjenjang yang diambil dari fitur-fitur dalam dataset. Setiap simpul dalam pohon mewakili keputusan berdasarkan fitur-fitur data untuk memprediksi kelas atau nilai target.
2. K-Nearest Neighbors (KNN):
- Cara kerja: KNN menentukan kelas suatu instance berdasarkan mayoritas kelas dari tetangga-tetangga terdekatnya di ruang fitur. Ketika mendapat data baru, algoritma menghitung jarak ke titik-titik terdekat dalam ruang fitur dan menentukan kelasnya berdasarkan mayoritas tetangga terdekatnya.
3. Naive Bayes:
- Cara kerja: Algoritma ini menggunakan teorema Bayes untuk memprediksi kelas dari suatu instance dengan mengasumsikan bahwa fitur-fitur yang ada dalam dataset adalah independen satu sama lain. Berdasarkan perhitungan probabilitas dari setiap kelas, algoritma ini menentukan kelas yang paling mungkin berdasarkan nilai fitur-fitur yang diberikan.
Soal 2
Berikut ini dataset kumpulan kondisi cuaca :
[{
Day: 'D1',
Outlook: 'Sunny',
Humidity: 'High',
Wind: 'Weak',
Play: 'No',
},
{
Day: 'D2',
Outlook: 'Sunny',
Humidity: 'High',
Wind: 'Strong',
Play: 'No',
},
{
Day: 'D3',
Outlook: 'Overcast',
Humidity: 'High',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D4',
Outlook: 'Rain',
Humidity: 'High',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D5',
Outlook: 'Rain',
Humidity: 'Normal',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D6',
Outlook: 'Rain',
Humidity: 'Normal',
Wind: 'Strong',
Play: 'No',
},
{
Day: 'D7',
Outlook: 'Overcast',
Humidity: 'Normal',
Wind: 'Strong',
Play: 'Yes',
},
{
Day: 'D8',
Outlook: 'Sunny',
Humidity: 'High',
Wind: 'Weak',
Play: 'No',
},
{
Day: 'D9',
Outlook: 'Sunny',
Humidity: 'Normal',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D10',
Outlook: 'Rain',
Humidity: 'Normal',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D11',
Outlook: 'Sunny',
Humidity: 'Normal',
Wind: 'Strong',
Play: 'Yes',
},
{
Day: 'D12',
Outlook: 'Overcast',
Humidity: 'High',
Wind: 'Strong',
Play: 'Yes',
},
{
Day: 'D13',
Outlook: 'Overcast',
Humidity: 'Normal',
Wind: 'Weak',
Play: 'Yes',
},
{
Day: 'D14',
Outlook: 'Rain',
Humidity: 'High',
Wind: 'Strong',
Play: 'No',
}]
Dengan menggunakan perhitungan Naïve Bayes, berikan perhitungan manual untuk memprediksi apakah seseorang akan bermain golf atau tidak berdasarkan keadaan cuaca pada hari tertentu dengan atribut dibawah ini :
{
Day : "Dx",
Outlook : "Rain",
Humidity : "High",
Wind : "Weak",
Play : "?"
}
Jawab:
Langkah pertama adalah menghitung probabilitas kelas 'Yes' (bermain) dan 'No' (tidak bermain):
Kita telah menghitung probabilitas yang diperlukan. Sekarang, gunakan rumus Bayes untuk memprediksi apakah seseorang akan bermain golf pada hari tertentu dengan atribut yang diberikan:
Setelah melakukan perhitungan, nilai dari P(Play=Yes∣Outlook=Rain,Humidity=High,Wind=Weak) adalah sekitar 0.606.
Sehingga, berdasarkan perhitungan tersebut, nilai Play berdasarkan kondisi Outlook=Rain, Humidity=High, dan Wind=Weak adalah Yes dengan probabilitas sekitar 0.606.
Berikut ini adalah list pertanyaan dari situs ini https://sites.google.com/anakbangsabisa.org/generasi-gigih-portal-pendafta/cara-mendaftar . Dikelola oleh YABB (Yasasan Anak Bangsa Bisa). Ceritakan pengalaman belajarmu yang paling sulit dan bagaimana caramu mengatasi masa tersebut? Yang tersulit adalah belajar mengenal diri sendiri. Sampai saat ini saya masih terus mempelajari bagaimana menjalani hidup yang lebih baik. Setiap hari bisa lebih baik dari hari sebelumnya. Cara saya dalam mengatasi kesulitan tersebut adalah dengan sering berkomunikasi dengan diri sendiri di setiap kesempatan. Biasaya di waktu pagi hari saya membuat video aktifitas harian untuk mendokumentasikan kegiatan harian. Di waktu senggang lainnya saya merutinkan diri untuk membuat artikel apa saja yang sedang saya pikirkan. Alhamdulillah dengan cara tersebut saya sedikit demi sedikit semakin mengenal karakter diri saya sendiri. Kenapa kamu tertarik untuk meneruskan karir di Industri Teknologi? Saya menyukai ind...
Question 1 : Jabbers are either vorpal or jubjub. If jabbers are jubjub, then they are also wocky. Jabbers are not vorpal. The statement "Jabbers are wocky" is: (true, false, uncertain) Answer: true
Belajar Penatausahaan SIPD Kemendagri Buku manual book bisa dilihat di sini . (725 halaman) PENGATURAN AWAL (hal. 2) User BUD membuat pengaturan kebijakan periode SPD (Per semester, triwulan dan bulanan) (hal. 4-6) User BUD melakukan pengaturan penandatanganan SPD (BUD, Kuasa BUD dan Distribusi Tanda Tangan) (hal. 7-13) Distribusi Tanda Tangan, input besaran Nilai Rentang, sehingga rentang nilai dari 0 sampai dengan besaran yang diinput akan ditandatangani oleh Kuasa BUD User BUD melakukan Input Besaran UP SK KDH (Uang Persediaan Surat Keputusan Kepala Daerah) (hal. 14-18) Nilai default besaran UP adalah 1/12 pagu anggaran dan bisa diedit sesuai kebutuhan User BUD membuat jadwal penatausahaan (hal. 19-26) Jadwal penatausahaan bisa diedit keterangannya dan bisa dikunci Penguncian jadwal penatausahaan adalah berfungsi untuk menutup jadwal PENGISIAN DPA, RAK DAN PELIMPAHAN KEGIATAN (hal. 27) Akun Kasubag Program mengisi RAK (hal. 28-56) Bisa mengisi sendiri atau didelegasikan k...

















Komentar
Posting Komentar
Semoga bermanfaat dunia dan akhirat